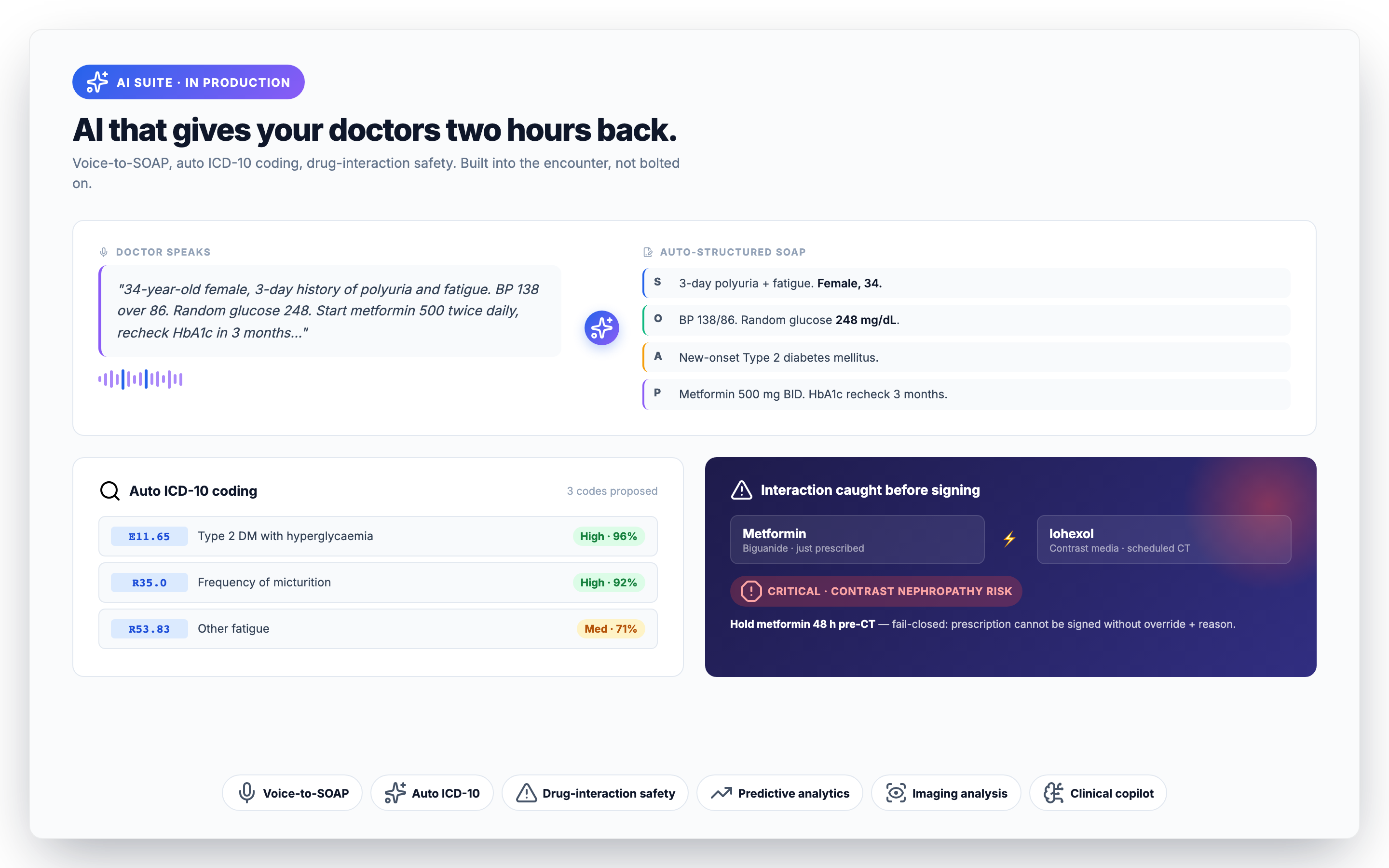
Voice-to-SOAP — get two hours of your day back
Speak naturally during the consult; Medixar produces a structured SOAP note (Subjective, Objective, Assessment, Plan) ready for one-tap save. In our private beta, the average time-to- save-note dropped from 11 minutes to under 90 seconds — about two hours per working day for a busy doctor. The model handles the major Indian languages (English, Hindi, Malayalam, Tamil, Telugu, Bengali, Marathi) and tolerates code-switching mid-sentence.
The structural assumption is that voice-to-SOAP is a draft, not a finished note. Every output flows through the doctor for sign-off; the workflow does not let you skip review. That single guard rail — "AI suggests, clinician decides" — is what makes the feature deployable in a real Indian practice. Read our honest evaluation.
Auto ICD-10 coding — fewer rejections, faster claims
ICD coding is the unglamorous but expensive half of clinical AI. Indian clinics under-code chronically because doctors do not enjoy looking up codes and the front desk does not know what to look up. Insurance claim rejections trace back to coding gaps a striking percentage of the time.
Auto-coding parses the assessment section of the encounter and proposes matching ICD-10 codes (and ICD-11 TM2 codes for AYUSH consultations). The doctor sees the suggestions, clicks the right ones, and moves on. Three improvements compound:
- Higher specificity — fewer "other unspecified" codes that flag for manual review.
- Faster claim turnaround — fewer rejections at the insurance layer.
- Better analytics — the practice owner finally has a clean breakdown of what they're treating.
Predictive analytics — surfaced where the decision is made
Predictions only matter if they reach the clinician at the moment they need them. Medixar surfaces four predictive models inline at the point of decision rather than in a separate dashboard:
- No-show probability — visible on every appointment in the day list. Front desk can over-book the high-risk slots and call the medium-risk patients to confirm.
- Readmission risk — appears on the discharge summary. A high-risk patient triggers a closer follow-up cadence automatically.
- Length-of-stay estimate — generated at admission. Bed planning becomes data-driven instead of gut-feel.
- 7-day bed-demand forecast — visible to the bed-management team daily. Surge planning is no longer reactive.
Models run on a Python FastAPI microservice. Re-training cadence: monthly with tenant-specific data; never with PHI from one tenant influencing another tenant's model.
Drug-interaction safety — the one that fails closed
The clinical copilot category gets over-promised. We're picky about what we ship under the AI banner because the wrong design causes harm. Drug-interaction checks are the example.
Every prescription runs a drug-interaction check before it can be signed. If the interaction database is unreachable, the system fails closed — the prescription cannot be created. Better to refuse a prescription than to silently miss a major interaction. The rejection emits a structured event so ops sees the signal; the doctor gets a clear message and can re-try once the database is back.
For AYUSH practices, the safety surface widens: cross-pharmacopoeia interactions (Ayurveda × Homeopathy, Unani × Siddha, etc.) run nine backends in parallel, and any partial backend failure is reported as a structured warning rather than silently passing. See the AYUSH page for detail.
Medical imaging analysis
AI-assisted analysis for X-ray, CT, MRI, and ultrasound. Severity classification + findings extraction integrated into the radiology workflow — the radiologist sees the AI overlay alongside the original image, with a confidence score and explanation. Findings are captured into the radiology report draft so the radiologist edits rather than starts from a blank page.
The radiologist always signs the report. Hospitals concerned about medico-legal exposure on AI-assisted reads should know: the legal sign-off rests with the radiologist, the same way it does for a CAD-assisted mammogram in 2018.
Agentic clinical copilot
The newest addition. The copilot watches the encounter as it builds and surfaces three kinds of nudge:
- Critical-value alerts — lab results that breach thresholds get a clear unacknowledged-result queue.
- Care-plan drafts — for chronic disease management, the copilot drafts a plausible plan based on the patient's history. The doctor edits 30%; the other 70% saves them typing.
- Documentation gaps — flags assessments that should have a diagnosis code attached, or a follow-up that should have a date.
What we deliberately do not ship: open-ended diagnostic suggestion. "Suggest the most likely diagnoses for this picture" is the area where current models are most likely to mislead, and where junior clinicians are most likely to over-trust the output. We will revisit when the safety profile matures.
Where does the data go?
Voice audio and clinical text are sent to Anthropic's Claude API for inference, then discarded. Anthropic does not use Medixar customer data to train their models — this is a contractual obligation in our agreement, not a courtesy. PHI never leaves a permitted processor. Full security architecture is here.
How to evaluate AI for your practice
A practical test plan we recommend before adopting any AI scribe:
- Pick one busy clinic day. Run the AI scribe on every consult.
- Time the doctor's time-to-save-note before and after.
- Audit the first ten notes manually. Note where the AI got things wrong.
- Check the coding-rejection rate for a month before and a month after.
- Make sure the workflow forces a human-in-the-loop sign-off.
We are happy to run this test with you on staging. Book a demo and tell us your specialty.